
I am a Ph.D. student at MMLab@HKU, the University of Hong Kong, supervised by Prof. Xihui Liu. I received my B.Eng. degree at the Department of Automation, Tsinghua University.
My research focuses on Generative models and Multimodal AI in Computer Vision. More specifically, I am currently dedicated to the development of visual tokenizers for better modeling of visual signals for generative AI models.
🔥 News
- 2026.02: EVATok is accepted by CVPR 2026!
- 2025.06: GigaTok is accepted by ICCV 2025!
- 2025.04: 🎉🎉 Proud to release GigaTok, the first work that successfully scales visual tokenizers to 3B parameters!
- 2024.10: 🎉🎉 LVD-2M: A Long-take Video Dataset with Temporally Dense Captions (NeurIPS 2024, D&B track) is released!
💻 Internships
- 2023.07 - 2023.09, Research Assistant, HKU-IDS
- 2024.02 - 2025.12, Research Intern, ByteDance-Seed
- 2026.02 - now, Research Intern, Tencent Hunyuan
📝 Publications
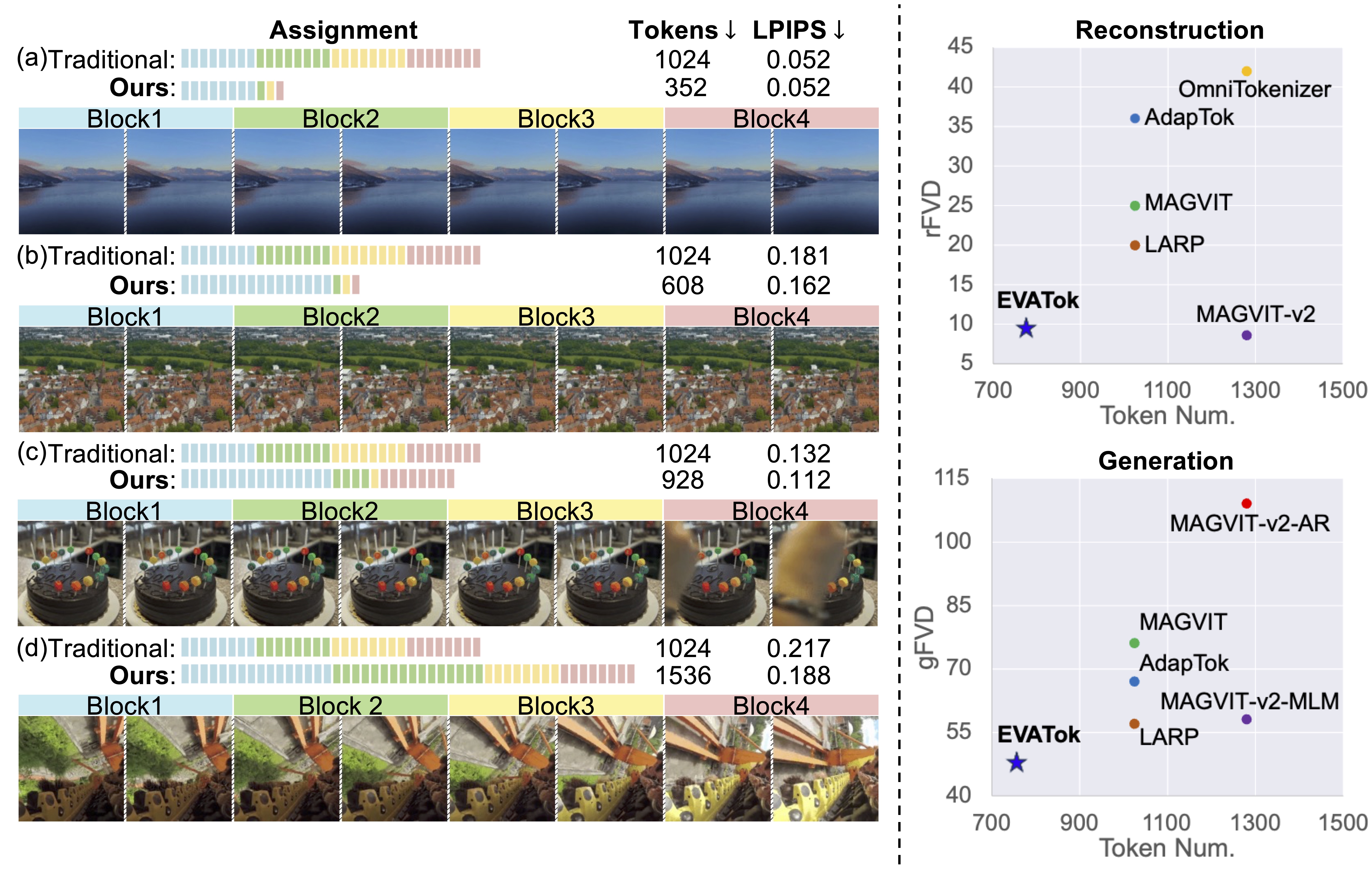
EVATok: Adaptive Length Video Tokenization for Efficient Visual Autoregressive Generation
Tianwei Xiong, Jun Hao Liew, Zilong Huang, Zhijie Lin, Jiashi Feng, Xihui Liu
- We propose an adaptive length video tokenization scheme to improve the efficiency of visual autoregressive generation.
- EVATok achieves significant speedup while maintaining high reconstruction quality and generation performance.
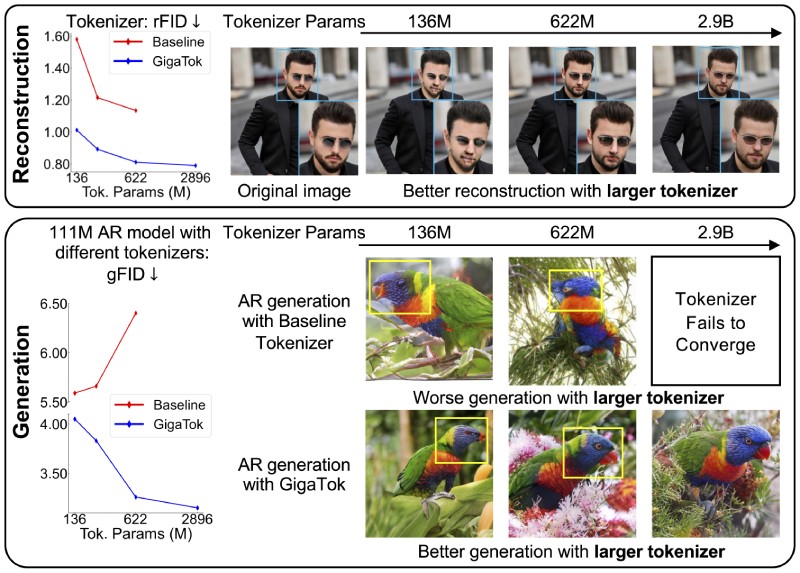
GigaTok: Scaling Visual Tokenizers to 3 Billion Parameters for Autoregressive Image Generation
Tianwei Xiong, Jun Hao Liew, Zilong Huang, Jiashi Feng, Xihui Liu
- We propose solutions for reconstruction vs. generation delimma for scaling tokenizers.
- GigaTok is the first work that successfully scales visual tokenizers to 3 billion parameters!

LVD-2M: A Long-take Video Dataset with Temporally Dense Captions
Tianwei Xiong*, Yuqing Wang*, Daquan Zhou, Zhijie Lin, Jiashi Feng, Xihui Liu
- We pay special attention to long-take videos without cuts.
- We propose a data pipeline for filtering high-quality long-take videos and the temporally dense captioning of the videos.
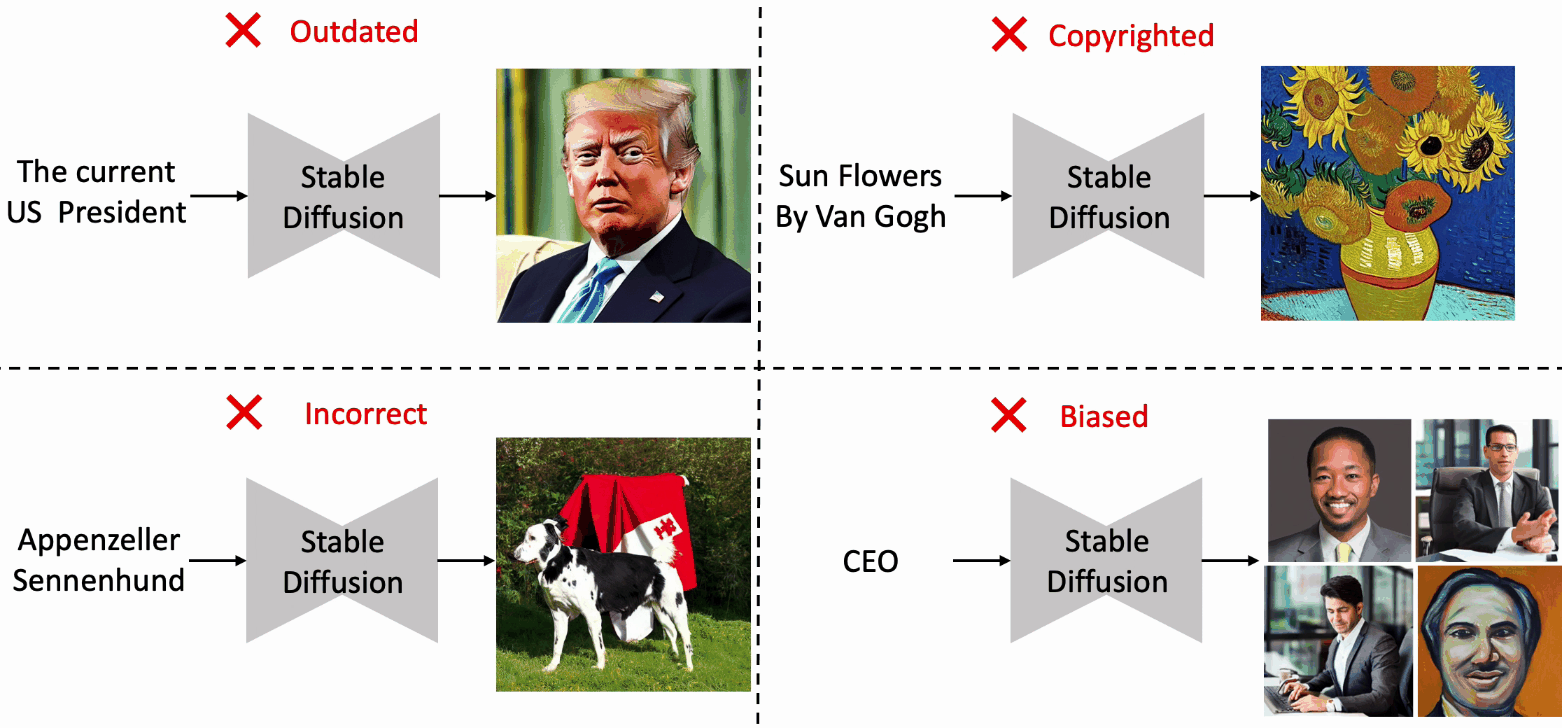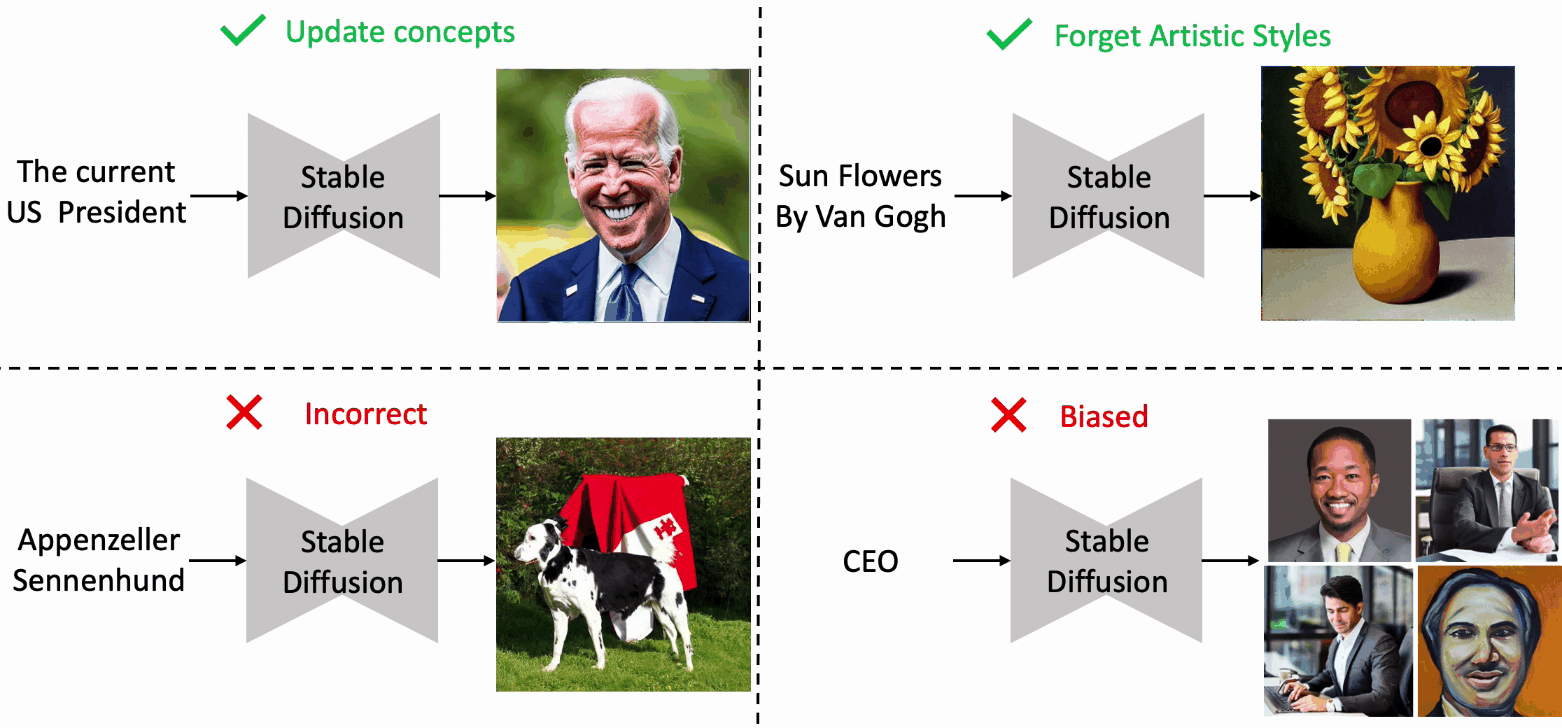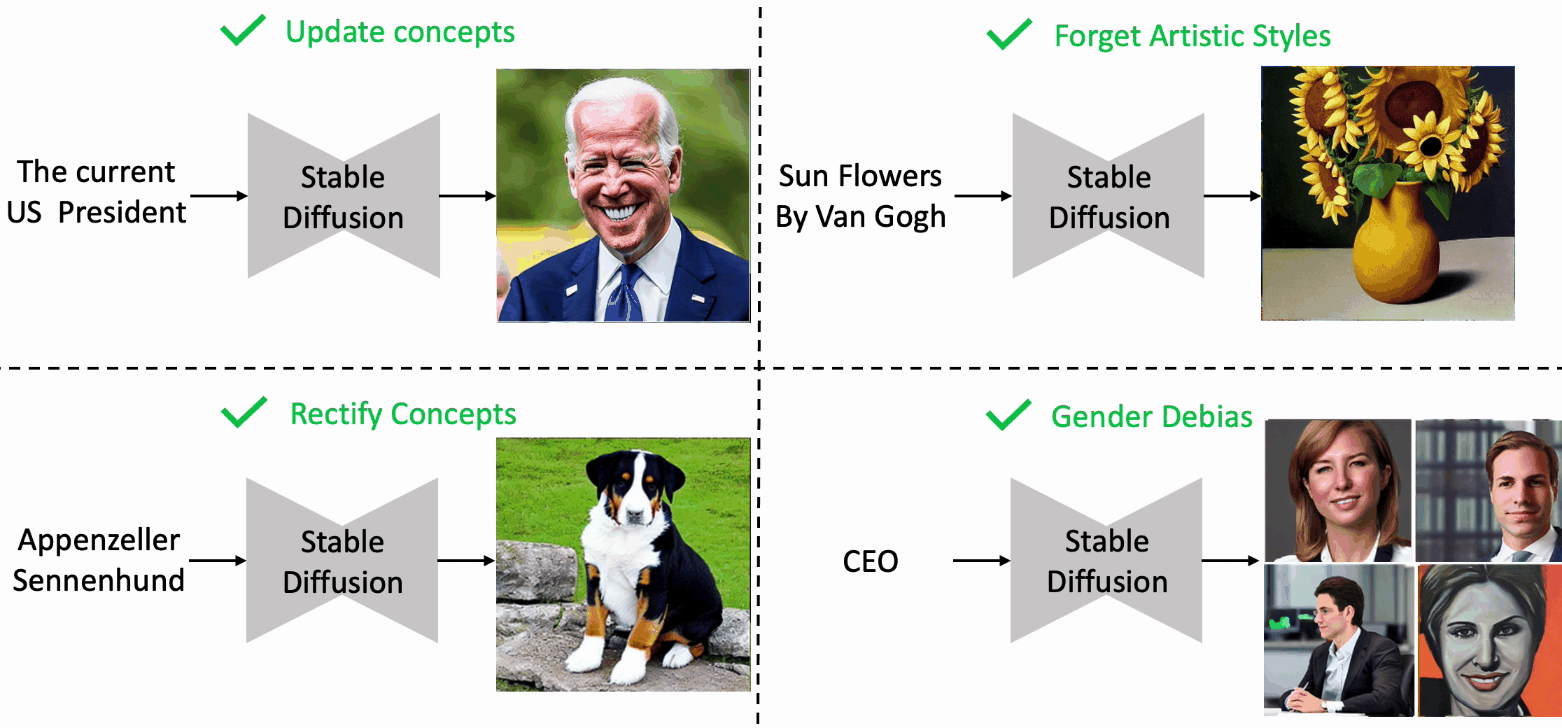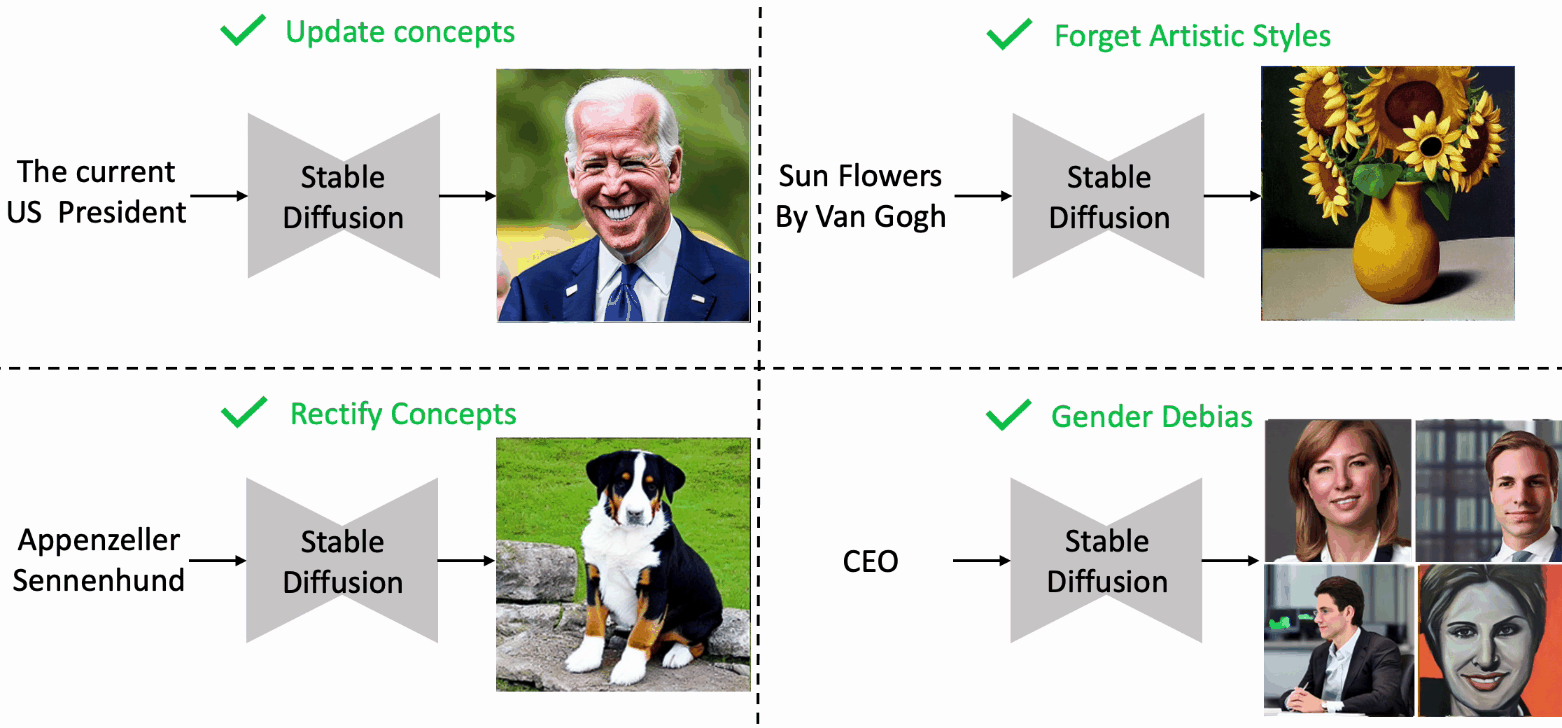
Editing Massive Concepts in Text-to-Image Diffusion Models
Tianwei Xiong*, Yue Wu*, Enze Xie, Yue Wu, Zhenguo Li, Xihui Liu
- EMCID can edit massive concepts in text-to-image diffusion models, with limited costs and minimal negative effects on the performances.
🎖 Honors and Awards
- HKU Presidential PhD Scholarship (HKU-PS) and Hong Kong PhD Fellowship (HKPF). 2024-2025
💬 Academic Services
- I served as a reviewer for CVPR and NeurIPS.